以下のようなスクレイピングでの問題を拝見しました。最近増えてきているスクレイピングを回避するサイトかなと思いましたので、簡単な回避策をご紹介したいと思います。

問題の確認
記述頂いたサイトにアクセスをし、Pythonのシンプルなコードでのスクレイピングができないことを以下のコードで確認しまいた。
import pandas as pd
url = 'https://kabu.dmm.com/service/us/stock_list/etf_list/'
data = pd.read_html(url, header = 0)
display(len(data))
display(data[0].head(5))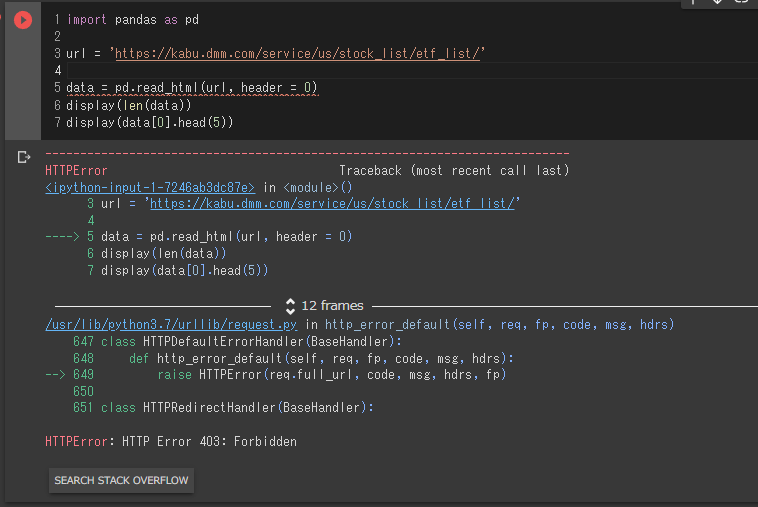
HTTPError: HTTP Error 403: Forbidden
ということで、スクレイピング防止の設定がされているのかもしれません。
場合によっては’User-Agent‘の設定を付けてあげて回避する方法もあるようですが、今回の例ではSeleniumを使って問題の解決を図りたいと思います。
使用するツール
使用するツールはGoogle Colaboratoryのpythonを使いますので、無料で、簡単に行うことができます。Google Colaboratoryについては以前書いた記事をご参照いただければと思います。
実際のコードとやっていること
Google ColaboratoryでSelenium実行するには以下のサイトが詳しいので、設定自体はこのサイトをご覧いただくのがよろしいと思います。
【Python】Google ColaboratoryでSelenium実行

Google Colaboratory上でSeleniumを利用するための環境設定部分が以下です。
#Chromiumとseleniumをインストール
print("前処理を開始")
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
実際のサイトへのアクセス部分は以下のようになります。
#ライブラリをインポート
from selenium import webdriver
import time
#---------------------------------------------------------------------------------------
# 処理開始
#---------------------------------------------------------------------------------------
# ブラウザをheadlessモード実行
print("\nブラウザを設定")
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(10)
# サイトにアクセス
print("サイトにアクセス開始")
driver.get("https://kabu.dmm.com/service/us/stock_list/etf_list/")
time.sleep(3)
ヘッドレスモードで動いているので、特に新規にブラウザが立ち上がるような事もなく、サイトにアクセスできている状態になります。
ここからがスクレイピングの部分ですが、いかのようになります。
import pandas as pd
dfs5 = pd.read_html(driver.page_source,flavor='bs4', header=0)
display(dfs5[0])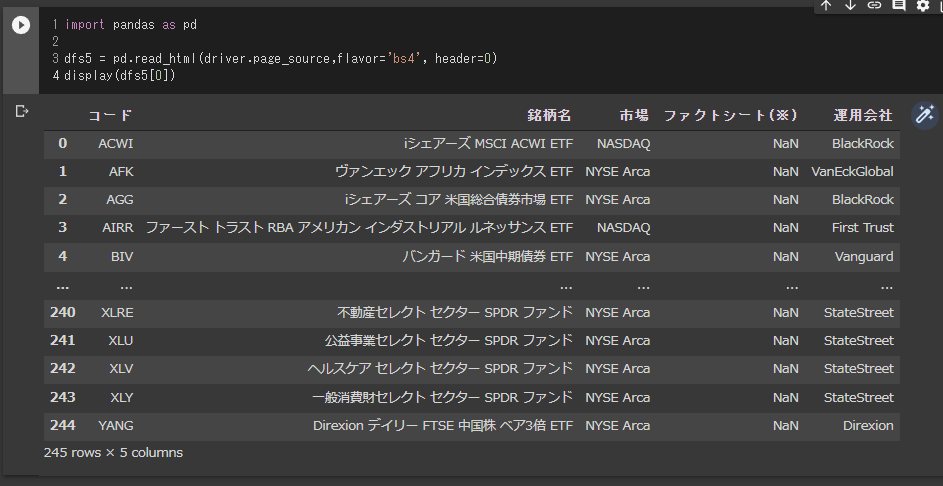
DataFrameにtableを読み込ませていますので、後はCSVで吐き出すなり、このDataFrameを再利用するなり、なんとでもできると思います。
出力データ
実際に出力したデータは以下の通りになります。
最後に改めてではありますが、参考にさせていただいたサイトを紹介させていただきます。
—
Pythonに関する記事をご紹介します。








コメント