
Twitter APIとPythonの連携、そしてそのデータを株式投資に利用していくアイディアをご紹介します。
2019/05/12に note に書いた記事になります。
2021/12/07時点で以下のコードはエラーなく動いていることを確認しています。
以下のツイートをしたところ多くの方に興味持っていただいたようなので、noteにまとめていきたいと思います。
この記事でできること
この記事でできることは以下の通りです。
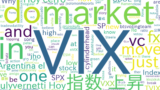
- ツイッターのツイートに VIX という言葉が含まれるものを取得します。
- そのツイートに VIX 以外にどんな言葉が含まれているか可視化します。
なんの役に立つのか?
マーケットのセンチメントが分かります。弱気な言葉、強気な言葉どんな言葉と一緒に使われているのかが分かります。目で見て、一つ一つ見ていくのは難しいです。
Pythonのwordcloudというモジュールを使うことで、VIXという言葉とともに使われた言葉を簡単に可視化することができます。
また、今回は VIX ですが、他の言葉(”暗号通貨”、”米国株 配当”、コスメといった皆さんの興味を持っている言葉)といったものを使って今、ツイッターで何がはやっていて、その言葉とともに何が一緒につぶやかれているかわかります。
この記事で使用するもの
以下の機能を使います。
・Google ColaboratoryのPython
・PythonからTwitter APIを利用するTweepyというパッケージ
・Pythonで日本語の形態素解析を行うJanomeというパッケージ
・Pythonで文章の単語出現頻度を可視化するWord Cloudというパッケージ
となります。そして最終的には、以下のような画像を作ることができます。
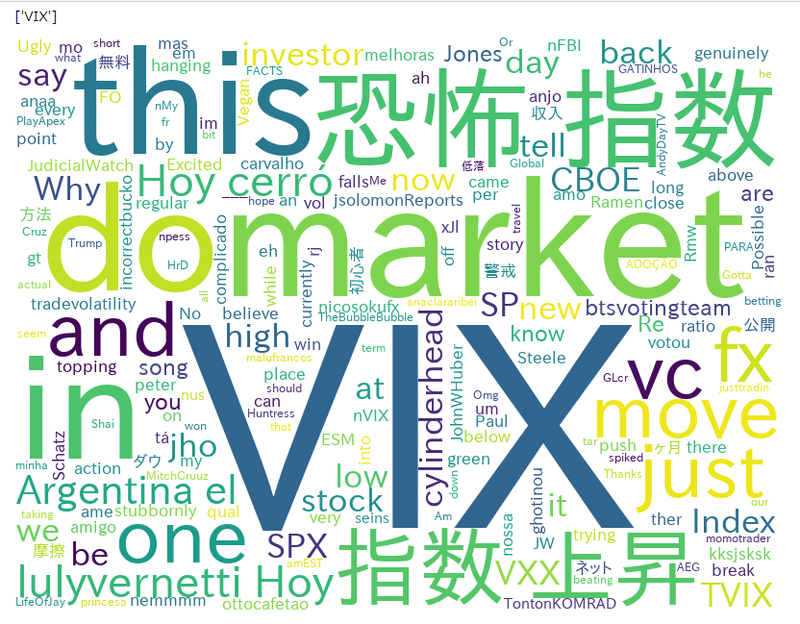
必須な知識
以下の条件に合致する人が対象になります。
・TwitterのAPIの申請を行っていること(※ない場合は、だいたい1週間程度で取得できます。)
・Pythonの基礎知識があること もしくは基礎知識取得に興味のある人
ツイッターのAPIの申請方法については、こちらをご覧ください。
私もここを参考にさせていただき申請を行いました。


最近は結構基準が厳しくなって、申請に手間取る人もいるとのことなので、人によってはここが一番手間のかかる部分かもしれません。
ここで、下段の方も同様にWordCloudを利用されていて、私も参考にさせていただいたのですが、この方の使われた形態素解析モジュールのMeCabが私はうまく動かなかったのと、日本語フォントの部分で少し手間取ったので、その部分の上昇が追加されたと思ってください。
Google Colaboratoryのpythonでの利用方法
以下の記事を読んで、Google Colaboratoryを利用できるようにしておいてください。こちらのnoteを見ると、Pythonの環境構築の方法が分かります。
パッケージのインポート
今回の利用では日本語を扱うので、日本語フォントの読み込みも行います。
!apt-get -y install fonts-ipafont-gothic
!ls /usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf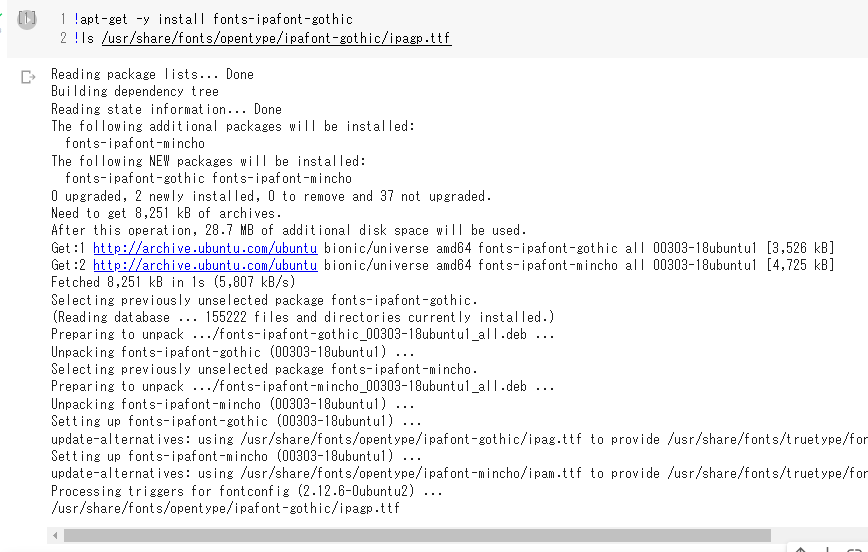
次に使用するモジュールを以下のコマンドでインストールします。
Google Colaboratoryの現在の状況ではすぐに使える状態だとおもいますが、自分のPC等で使われる方はインストールしてください。
!pip install tweepy
!pip install janome
!pip install wordcloud
これでモジュールが利用可能な状態になりました。
Web APIの認証キーのセット
import tweepy
#Twitter APIを使用するためのConsumerキー、アクセストークン設定
consumer_key = '<Twitter API申請して取得したConsumer_key>'
consumer_secret = '<Twitter API申請して取得したConsumer_secret>'
access_token = '<Twitter API申請して取得したAccess_token>'
access_token_secret = '<Twitter API申請して取得したAccess_secret>'
# Creating the authentication object
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth,wait_on_rate_limit = True) ツイッターでAPI経由で大量にアクセスを入れるとサーバーに負荷もかかりますし、API制限を超えるとAPIの利用不可になる場合もあるようです。
api = tweepy.API(auth,wait_on_rate_limit = True) の ,wait_on_rate_limit = True の部分でアクセス待ちをするようです。つけておいたほうがいいとも思います。
ツイートの取得
tweetCount1=80
keywords=["VIX","恐怖指数"]
import pandas as pd
df3=pd.DataFrame(columns=["created_at","name","text"])
for j in range(0,len(keywords)) :
public_tweets = api.search(q=keywords[j],count=tweetCount1)
for i in range(len(public_tweets)):
df3.loc[tweetCount1*j+i,"created_at"]=public_tweets[i].created_at
df3.loc[tweetCount1*j+i,"name"]=public_tweets[i].user.screen_name
df3.loc[tweetCount1*j+i,"text"]=public_tweets[i].text
print(len(df3))
tmp2=df3.copy()
tmp2["created_at"]=pd.to_datetime(tmp2["created_at"])
tmp2=tmp2.sort_values("created_at", ascending=False)
display(tmp2.head(10).append(tmp2.tail(10)))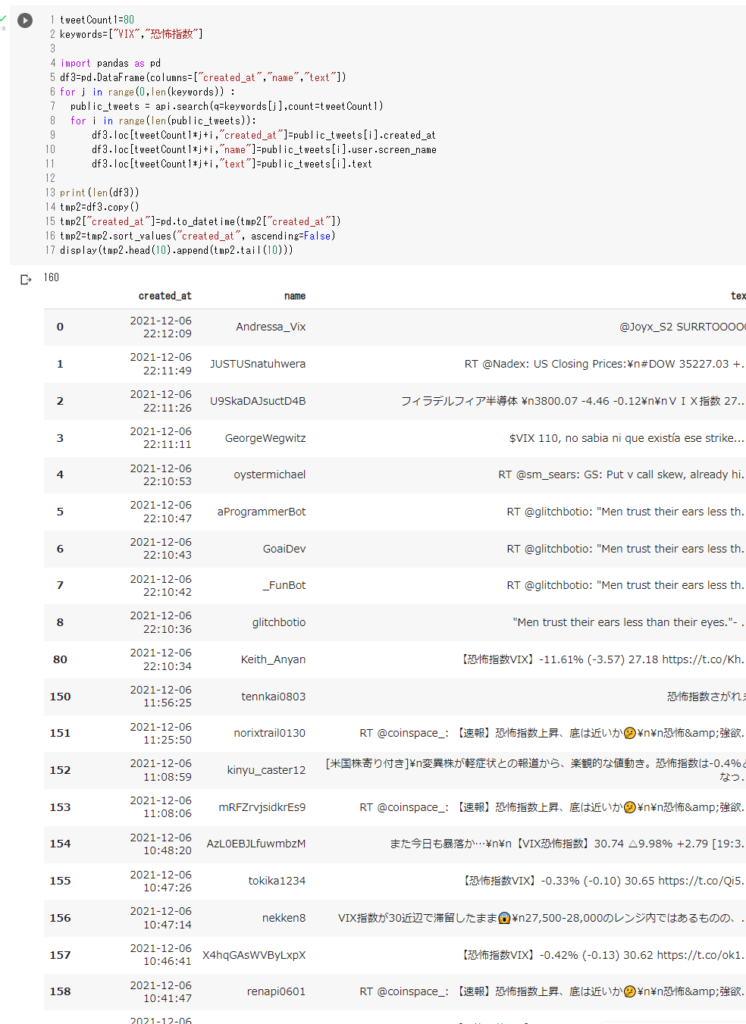
今回の例では VIX と 恐怖指数 の二つの言葉で80件ずつツイート検索を行っています。もちろん一つでも構いませんし、2つ以上の複数個でも構いません。
ただ、一度のAPIアクセスできる上限などもあるので、
(検索キーワード)x(ツイート件数)が大きすぎない数字にする必要があります。また、15分間にアクセスできる回数も制限がありますので、頻繁にアクセスして、サーバーに負荷を与えるのはお控えください。場合によってはAPIの使用をはく奪される場合があります。
形態素解析・単語出現頻度を可視化
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
text = ''
line = str(tmp2.text)
tokens = tokenizer.tokenize(line)
for token in tokens:
parts = token.part_of_speech.split(',')
if (parts[0] == '名詞'):
text = text + ' ' + token.surface
stop_words = [ u'https', u'de', u'na', u'com', u'RT', u'id', u'co',
u'The', u'year',u'of', u'AS',u'is', u'今日', u'VIX',u'恐怖指数',\
u'amp',u'恐怖',u'指数', \
u'よう', u'てる', u'いる', u'なる', u'れる', u'する', u'ある', u'こと', u'これ', u'さん', u'して', \
u'くれる', u'やる', u'くださる', u'そう', u'せる', u'した', u'思う', \
u'それ', u'ここ', u'ちゃん', u'くん', u'', u'て',u'に',u'を',u'は',u'の', u'が', u'と', u'た', u'し', u'で', \
u'ない', u'も', u'な', u'い', u'か', u'ので', u'よう', u'']
## 引き続きWordCloud
from wordcloud import WordCloud
wordcloud = WordCloud(background_color="white",
font_path="/usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf",
width=800,height=600,stopwords=set(stop_words)).generate(text)
wordcloud.to_file("./test.png")
from IPython.display import Image,display_png
display_png(Image('test.png'))中段にある stop_words の部分で検索キーワードによって除外したほうがいい単語を設定しています。また、最初に行った日本語フォントパッケージのインストールを行わないと日本語化以下のように文字化けすることがあるので、気を付けてください。

この画像はGoogle Colaboratory上に test.png の名前で出力されていますので、それを利用することもできますし、自分のPCのスクリーンキャプチャー機能などを使って画像にできると思います。
以上、長文お読みいただき大変ありがとうございました。
今後も皆さんのお役に立てればと思います。
また、ツイッター社にも、このような高機能なアプリケーションとその機能の一般ユーザーへの開放していただいたことに感謝いたします。
Python関係の記事







コメント