OpenAIのChatGPT(超高性能チャットAI)の注目度が最近非常に上がっています。
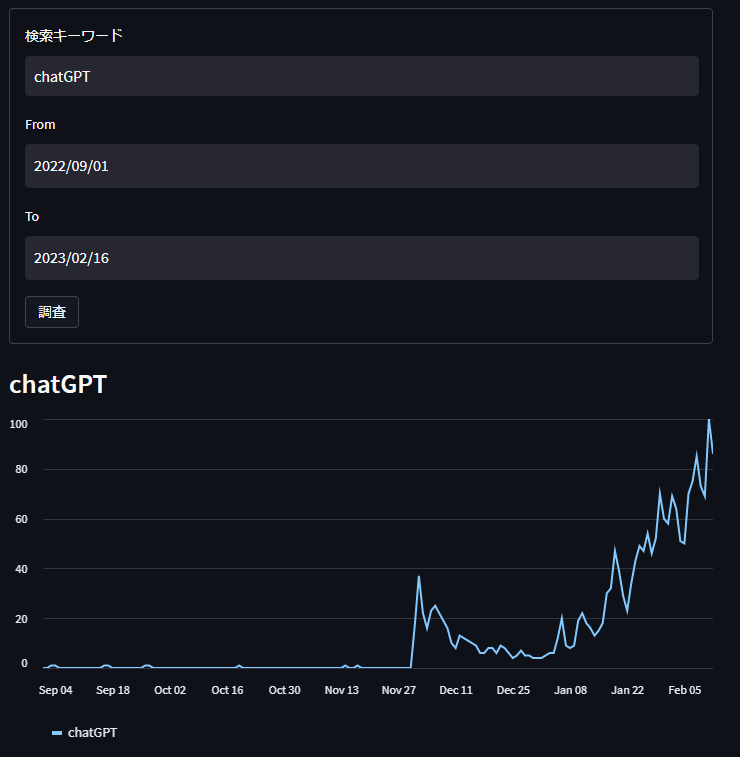

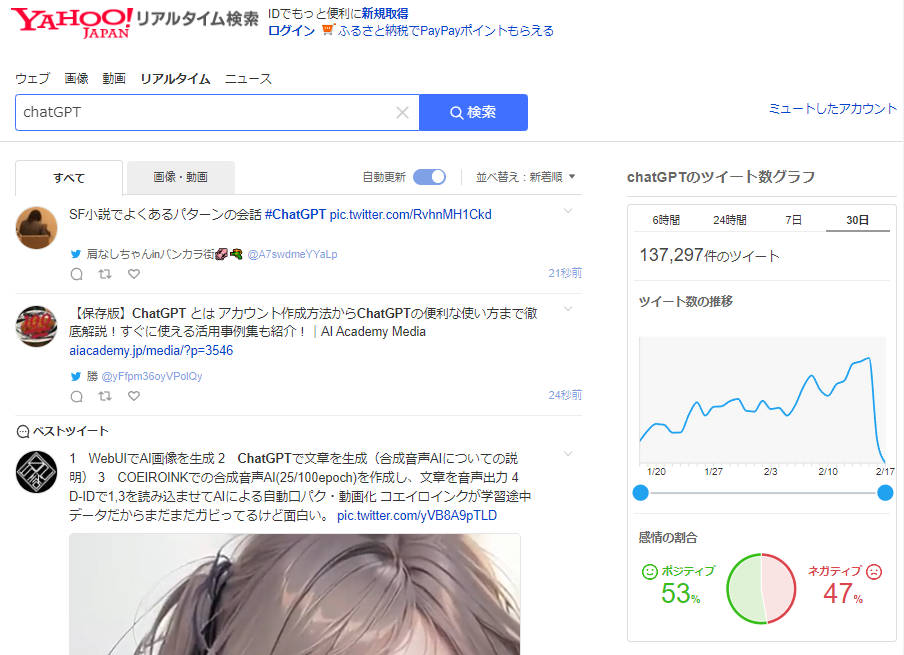
そのOpenAIが提供している音声認識モデルWhisperも高速高精度化しているようです。文字起こしソリューションとして、クラウド・OpenAI側にデータを渡さない、セキュアな環境での使用が可能という事で議事録生成であったり、他の翻訳サービスと合わせての動画からの文字起こし+翻訳など、”実務で役に立つサービス”に成長しそうな予感がします。
実際にどのくらいの精度や速度なのかを確認してみたいと思います。
実際に作成したWebアプリ
Your browser does not support iframes.
注意:iOSのセキュリティの関係でブログに埋め込んだ状態では表示できない場合があります。その場合は以下のリンクから直接に新規のタブとして表示てください。

文字起こしを行いたいYouTubeの動画URLを入力したのち、一旦音声ファイルにダウンロードし、その音声ファイルをWhisperのモデルを選択して、実行ボタンを押すと文字起こしができるシンプルなWebアプリになっています。
使用上の注意
選択動画の長さ
無料のStreamlitというサービスを利用しています。いったん選択したYouTube動画を音声のみダウンロードし、それをWhisperに認識させています。ですので、音声のダウンロードに時間がかかりますので、10分以上など長い時間の動画の扱いは少し難しい場合があります。また、短時間に何度もダウンロードなど行っているとYouTubeの側から一定時間アクセス禁止の制限を受ける場合があります。
Whisperのモデル
Whisperの言語認識モデルには5種類あり、スピードと正確性にはトレードオフの関係があります。また、使用するメモリサイズも精度を上げようとすると大きなサイズを必要とします。たまにメモリ不足という事で強制終了する場合があります。


実際の例
2ステップを踏むことになります。
1.YouTubeからダウンロードで動画の音声のみを抽出
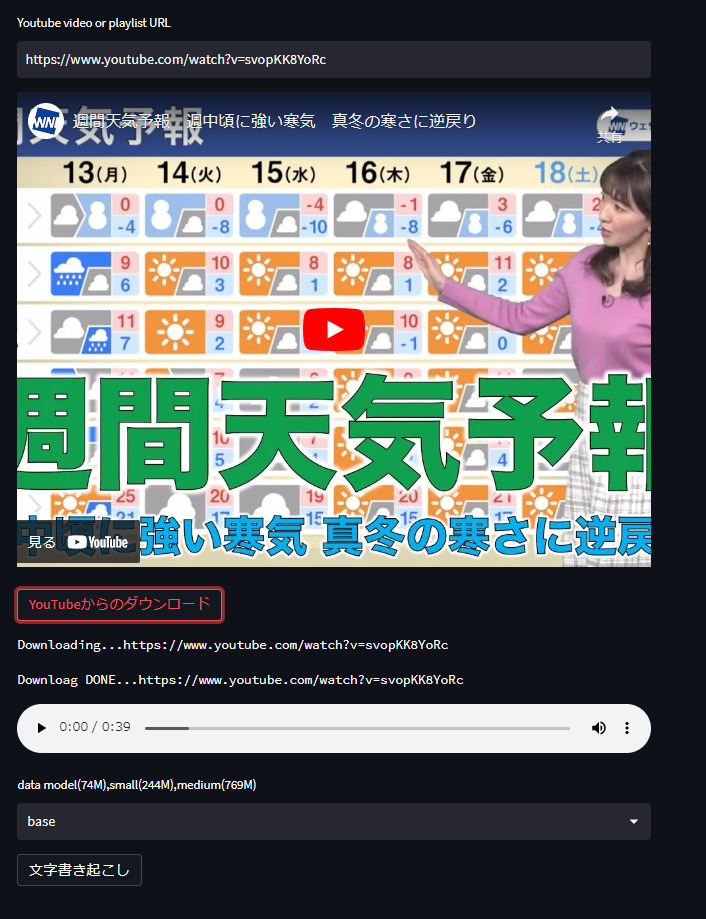
ダウンロードが終了した時点で音声の確認ができます。
今回の例では事前にダウンロードした音声ファイルがある状態です。
モデルを使った文字書き起こし
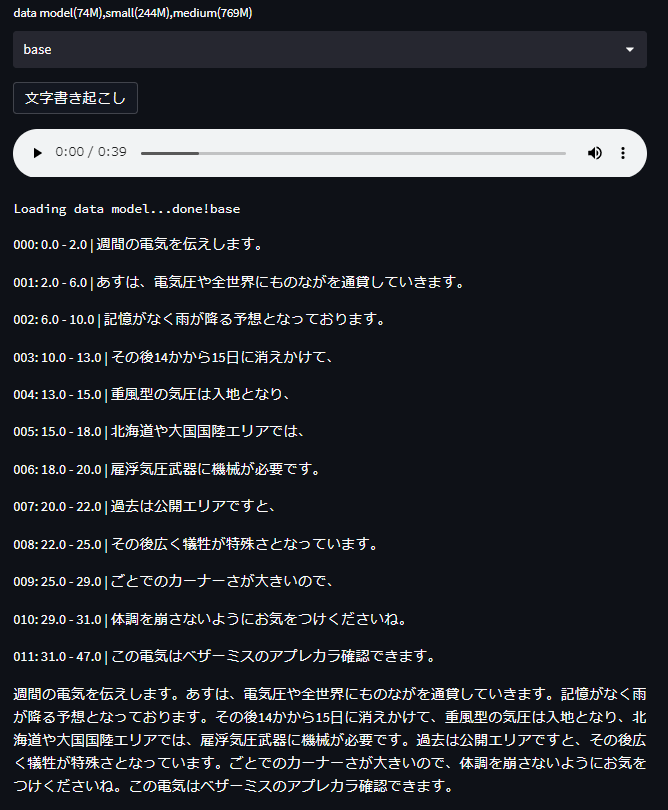
今回の例では簡易のbaseモデルを使った例になります。
モデルごとの違い
baseモデル
「週間の天気」が「週間の電気」などとなっているようです。
smallモデル
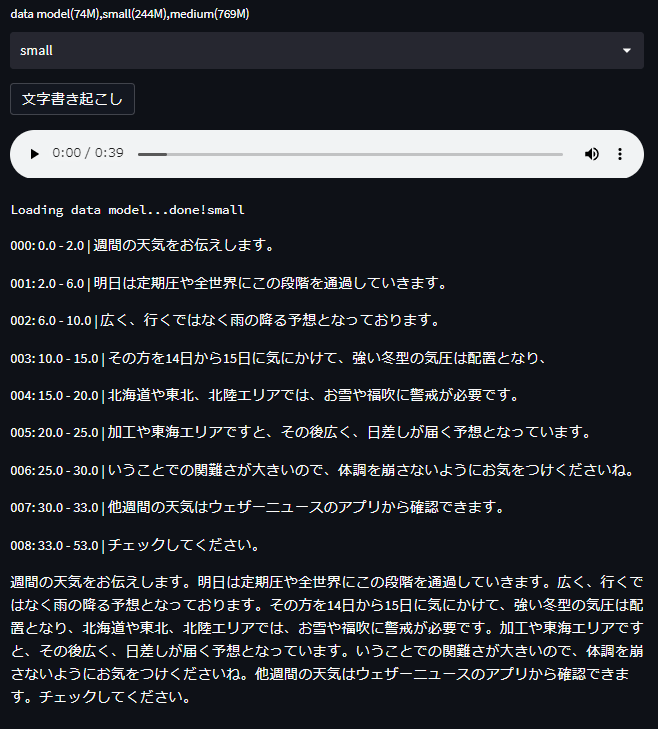
「低気圧」が「定期圧」となっていたり、微妙な違いが目につきます。
medium
Streamlitのサーバーでmediumにするとエラーが起きたりします。
日本語のモデルが1.4GB程度あったりするので、無料のサーバー上で動かすにはサイズが大きすぎるようです。
同じコーディングで自身のPCで行った文字書き起こしの結果は以下のようになります。
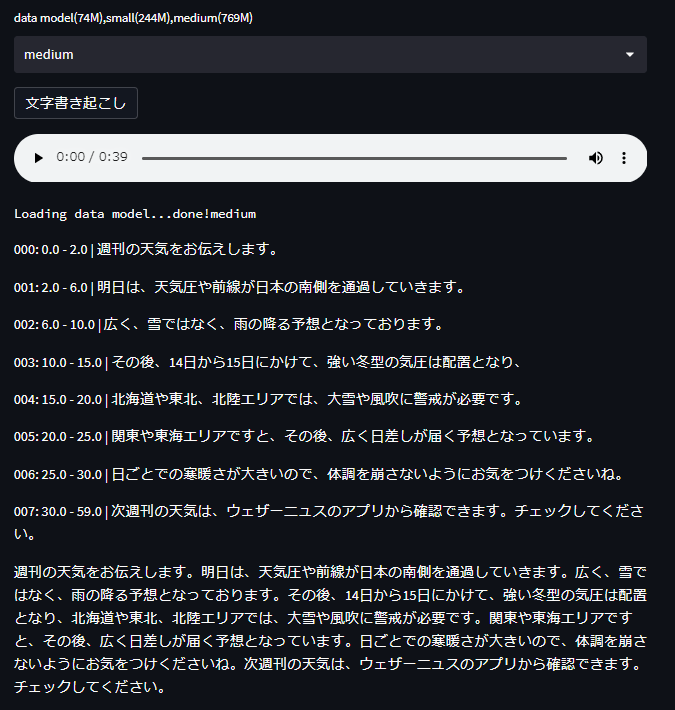
「天気」は認識していますあ、「低気圧」が「天気圧」となったりして惜しいですね。
英語
FRB議長パウエル氏のコメントは以下のように文字起こしができます。
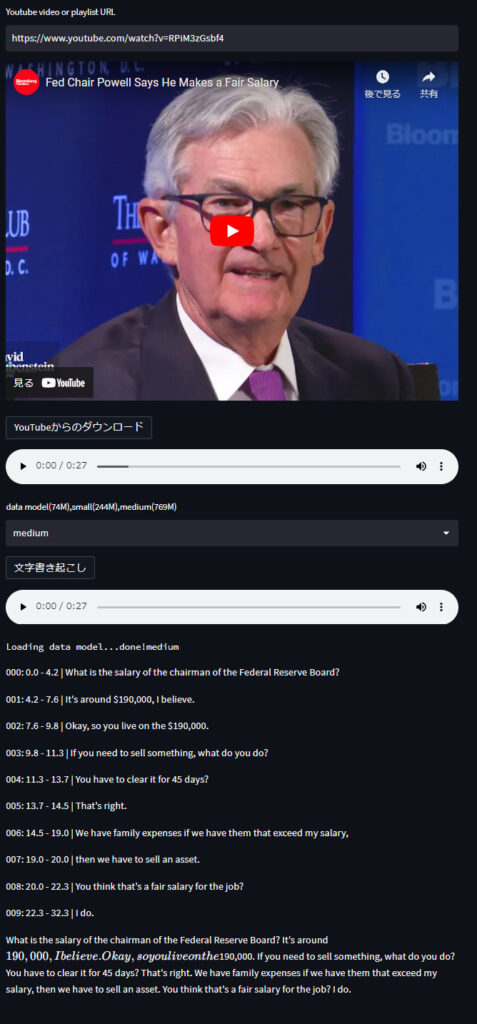
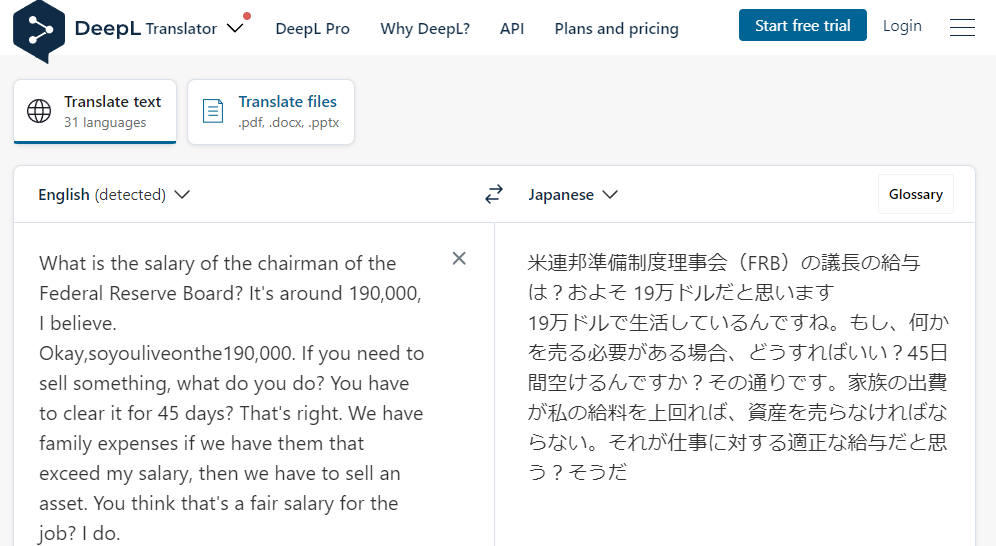
のように文字起こし&翻訳も可能です。
AIやPython関係の仕事効率化について
以下のような記事も書いています。興味のある方は参考にしてみてください。




—
Pythonや課題解決に関する記事をご紹介します。







コメント