読者の方から、問い合わせをいただいたのでフィードバックとコメントをお返ししたいと思います。
質問、問い合わせ
質問としてはとあるサイトをスクレイピングしたいという物と、それが問題ないのか、という物でした。サイト自体は以下のサイトになります。
http://kabupro.jp/edx/E12208.htm
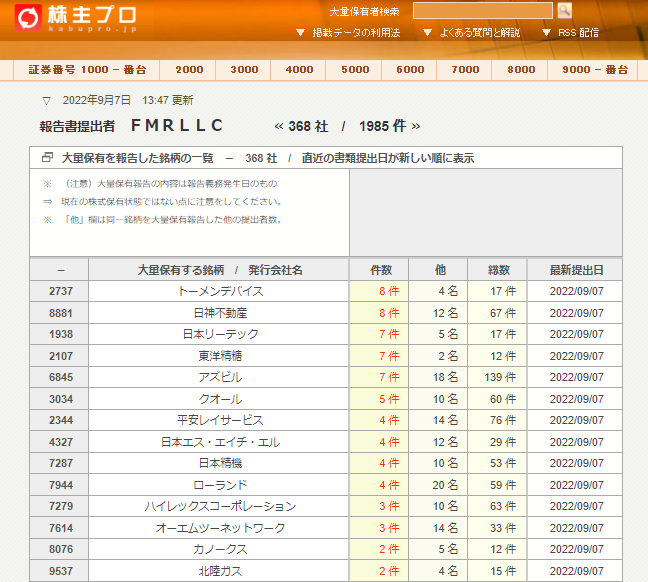
特定の機関投資家の大量保有を報告した銘柄の傾向を調査したいという事でしょうか。
目標とすること
そのサイトのデータを個人的な分析などで利用することとします。
使用するツール
使用するツールはGoogle Colaboratoryのpythonを使いますので、無料で、簡単に行うことができます。Google Colaboratoryについては以前書いた記事をご参照いただければと思います。
実際のコードとやっていること
実際のコードは以下の通りです。
import pandas as pd
url = 'http://kabupro.jp/edx/E12208.htm'
data1 = pd.read_html(url)
display(len(data1))
display(data1[0])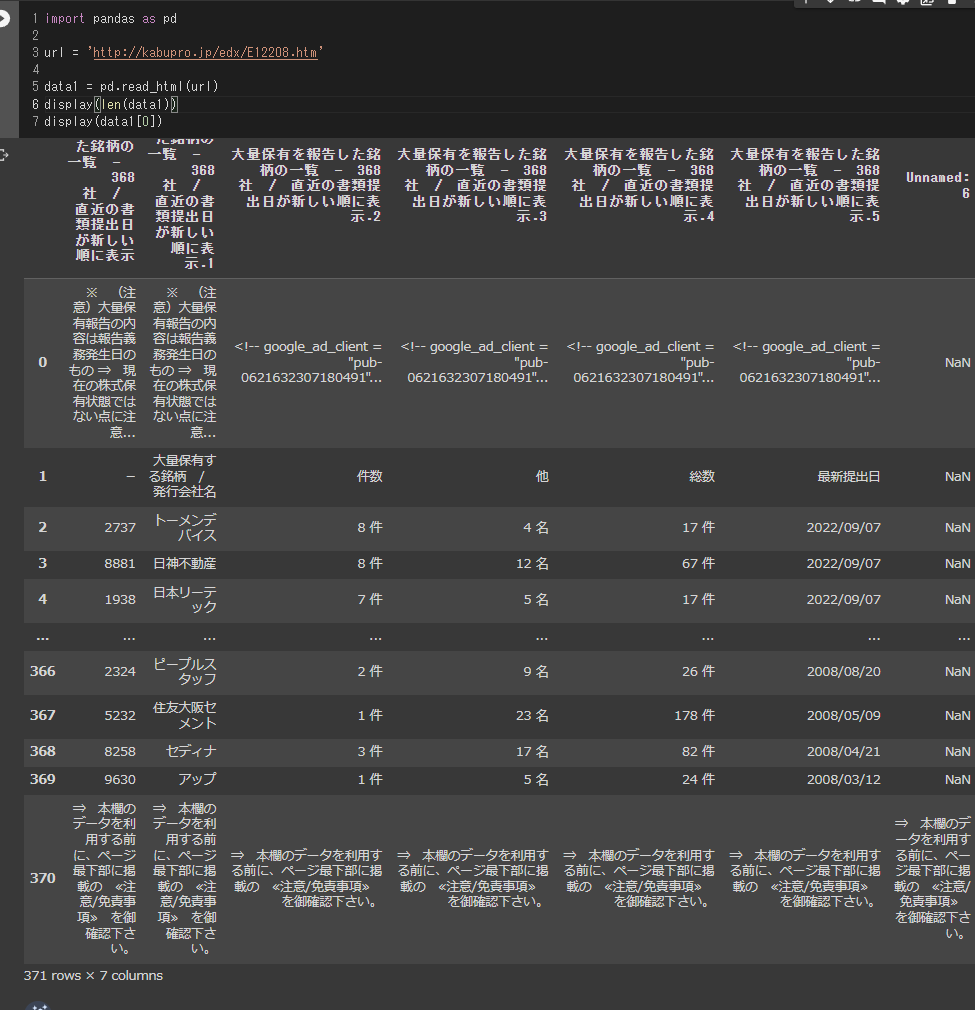
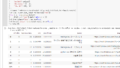
スクレイピング自体は問題なのですが、気になる点としてはヘッダー情報がピボットテーブルの形式になっていたり、最後の行が不必要な情報になっている事でしょうか。実際画像を見ても、最初の行がテーブルの結合のような形で恐らく広告などがあるようにも見えます。
どのようにすればこのあたり、分析に使いやすいようにデータ取得できるのでしょうか?
改善策1
ヘッダー情報がピボットテーブルであることを明示的に示してあげると良いと思います。
以下の例はいかがでしょうか?
data2 = pd.read_html(url, header =[0,2])
display(len(data2))
display(data2[0])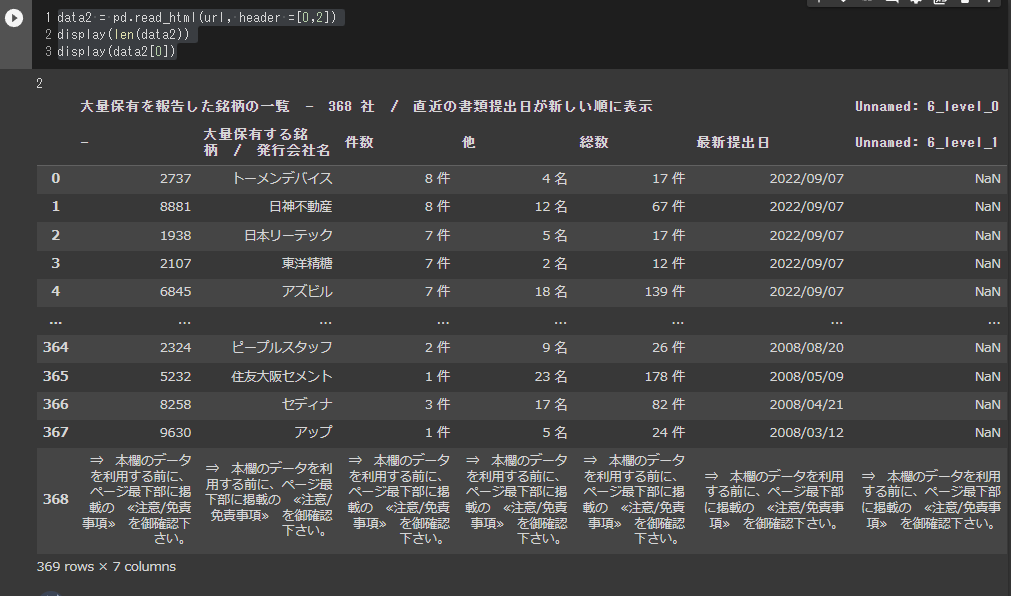
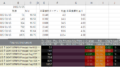
ヘッダー部がすっきりしたように思えます。ちなみに列名については以下のようになっているようです。
display(data2[0].info())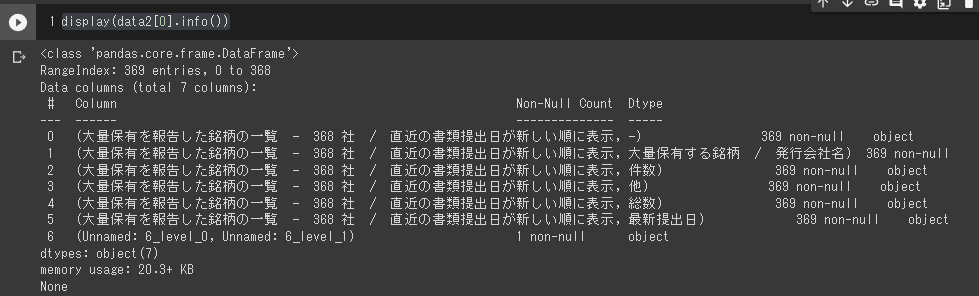
改善点2
列名が長いので、シンプルなものに変更し、最後行のデータは削除したいと思います。
table1=data2[0][:-1].copy()
table1.columns = ['code', '発行会社名', '件数', '他', '総数', '最新提出日','unname']
display(table1)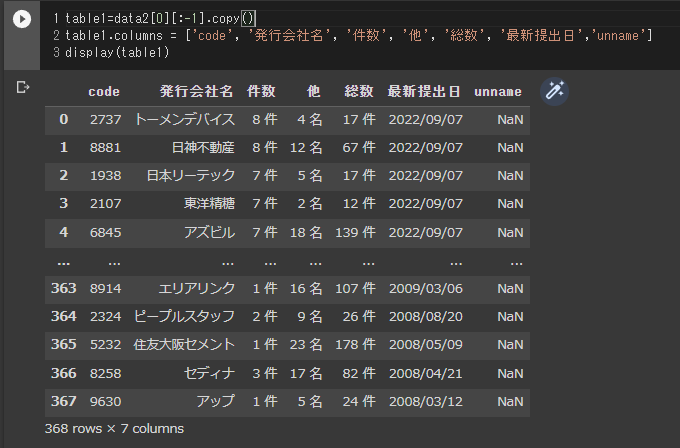
どうでしょうか。最初のデータよりは見やすくなったのではないでしょうか。
データ分析の7割から8割はデータの準備というのが自分の持論でもあるのですが、このような作業しやすいデータであれば、今後いろいろ分析してみようという気になるかもしれませんね。
スクレイピングについて
スクレイピングの注意点という物もあります。


スクレイピングで取得したデータを販売するとかであると問題があると思っています。
スクレイピングのために他のユーザーのアクセスに支障が出るなどの頻度でアクセスするのはよくありません。
上記のような点を勘案しながら常識的な使用を心がけてください。
—
Pythonに関する記事をご紹介します。








コメント