Pythonは遅いと言われることもありますが、ポイントを押さえた使い方をすると十分処理スピードを速い状態にできます。本記事ではfor文とそれ以外のコーディングでどのくらいスピードが違うかを示します。
また、本記事以外でも【コピペで動く!】Pythonで1.5GBのcsvファイル読み込み高速化:1分5秒⇒4秒程度 DASK , pickle (Pythonコードあり)にてPythonの高速化についてご紹介しています。

目標とすること
for文でできることを他のコマンドを使って高速に実行することを目指します。
使用するツール
使用するツールはGoogle Colaboratoryのpythonを使いますので、無料で、簡単に行うことができます。Google Colaboratoryについては以前書いた記事をご参照いただければと思います。
実際のコードとやっていること
実行するデータの作成する部分までをまずはコードでお示しします。
import pandas as pd
import numpy as np
import datetime
start_date = datetime.date(1990,1,1)
end=datetime.date.today()
date_df = pd.DataFrame(pd.date_range(start_date, end, freq='B').date, columns=['date'])
date_df["value"]=np.nan
display(date_df.head().append(date_df.tail(10)))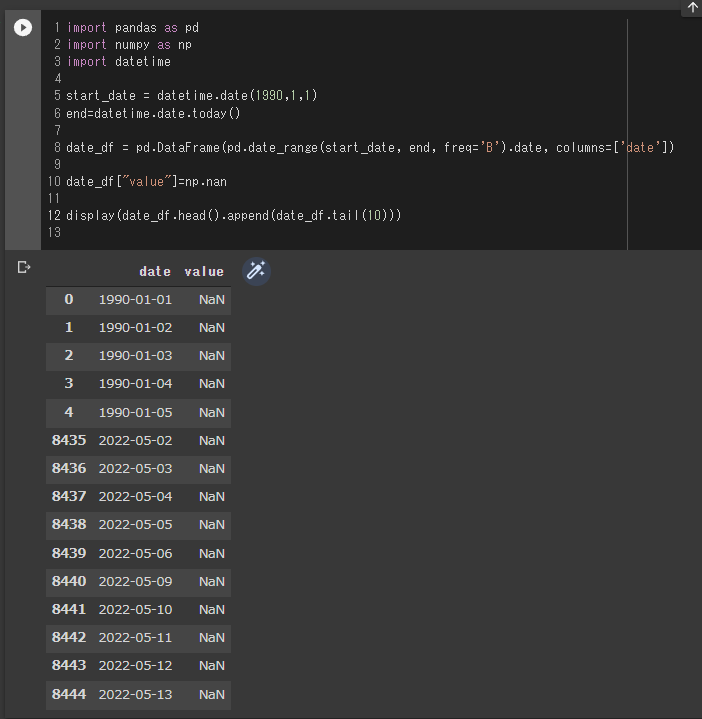
空のDataFrameを作成し、1990/01/01から今日(2022/05/13)までの毎営業日(月曜 – 金曜)で日付を入れていきます。今回の例では8400行の列が作成されています。2022/05/06が金曜日で、次の行が2022/05/09月曜日になっているのと見て取れると思います。
株価や他の指標的な物を想定して、ランダムに値を次の列に入れていきます。
import random%%time
for i in range(len(date_df)):
date_df.loc[i,"value"]=random.randint(0,len(date_df))
display(date_df.head().append(date_df.tail(10)))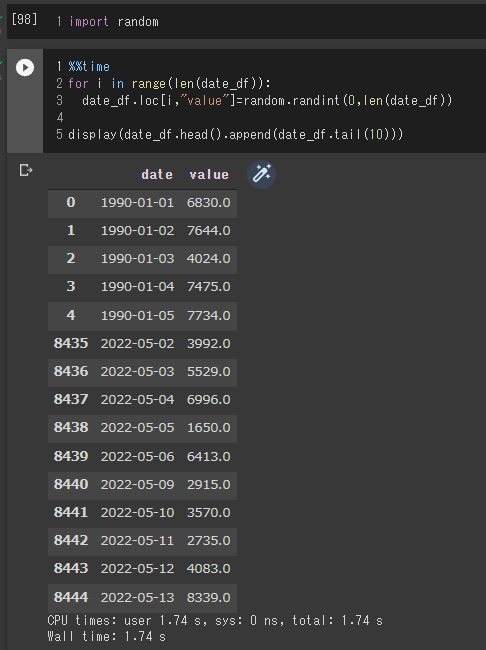
Google Colaboratoryの %%time のコマンドを使うことでそのセルでの実行時間を確認できます。
今回の例では実行時間は1.74秒という事になります。
for文の場合
for文の場合の例を以下に示します。
%%time
date_df["FOR"]=np.nan
for i in range(len(date_df)):
if date_df.loc[i,"value"] % 5 == 0:
date_df.loc[i,"FOR"] = 5
display(date_df.head().append(date_df.tail(10)))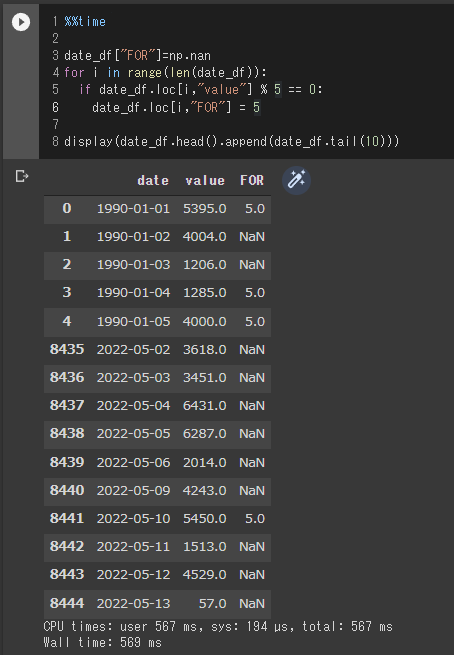
value列の値が5で割り切れる場合はFOR列に5という値を入力するコードになります。
実際の実行時間は569ミリ秒であることが分かります。
locを使う場合
locを使う場合の例を以下に示します。
%%time
date_df["loc"]=np.nan
date_df.loc[date_df["value"] %5 == 0,"loc"] = 5
display(date_df.head().append(date_df.tail(10)))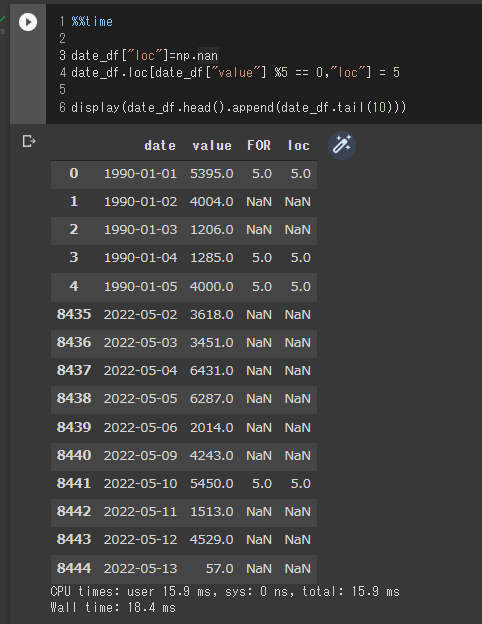
これもvalue列の値が5で割り切れる場合はFOR列に5という値を入力するコードになります。
実際の実行時間は18ミリ秒であることが分かります。
for文に比べて非常に早く、30倍相当早く実行されています。
ちなみにこのlocを使う分については以前の記事
【コピペで動く!】VIXと米国株指数の関係 コロナ前・コロナ後 Pythonコードあり【違いをみつけろ!】

「1月の相場が高ければ、その年の相場は高くなる」は本当か?Pythonで自分で調べてみよう!(Python コードあり)【コピペで動く!】Twitterで出てくる知見は本当か自分で調べてみよう。5
などでも扱っています。
lambdaを使う場合
lambdaを使う場合の例を以下に示します。
%%time
date_df["lambda"]=np.nan
date_df["lambda"]=date_df["value"].apply(lambda x: 5 if x %5 == 0 else np.nan)
display(date_df.head().append(date_df.tail(10)))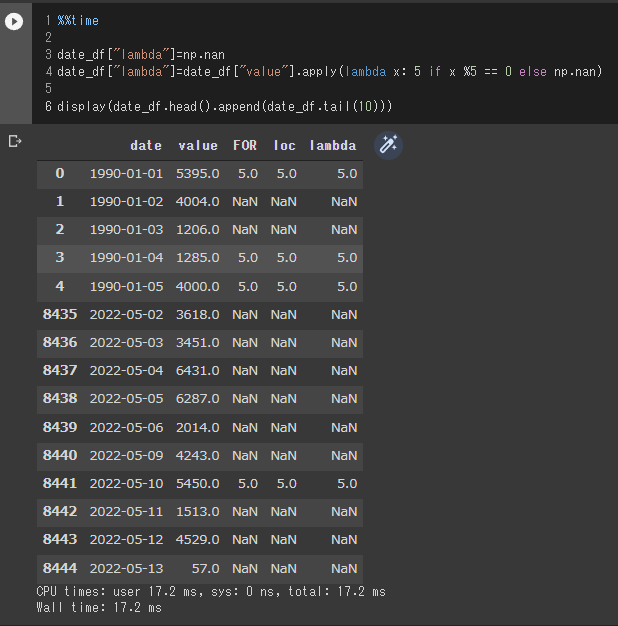
これもvalue列の値が5で割り切れる場合はFOR列に5という値を入力するコードになります。
実際の実行時間は17ミリ秒であることが分かります。
これもlocを使う場合と同様for文に比べて非常に早く、loc同様30倍程度早く実行されていることが分かると思います。
今回は8000行の日足での想定でしたが、分足や多数の列が存在する場合など、よりこの速度の改善が効いてくると思います。
結論
上記以外にもPythonのスピードアップを行う方法はあると思います。
ポイントを押さえた改善や施策で今回の例では約30倍高速に処理ができました。
特にPythonのfor文は速度の遅さが指摘されることが多いので、今回のような打開策は知識として知っておくと有用かなと思います。
この記事が皆さんのお役に立てば幸いです。
—
Pythonに関する記事をご紹介します。










コメント
for文が遅いというのもありますがデータフレームへのアクセス回数が違うのが本質的な違いで、むやみにループを回さす一気に処理することが効いていると思いますがあってますか?
匿名様 コメントいただきありがとうございます。
私は特別ボトルネックになっている工程がどこにあるのか解析するのが専門ではないので、確定的なものを申し上げられるほどの知識を残念ながら持ち合わせておりませんが、for文でなくてもやりたいと思っていることができたり、実務家レベルでの目先の課題の解決方法という意味で、とらえてもらえればと思います。どうしてもPython自体が遅い、forがネックというような言われ方も多いので、その先入観をなくすことができればと思っています。
直接的な回答にはなってないですが、ご理解いただけますと幸いです。TF