PythonでのCSV読み込みの高速化についてのご紹介します。読み込むデータは株価データなど、時系列データを今回は利用します。
2019/04/23 に note で書いた記事になります。

ハードウェアの進化や機能の深化でかかる時間などが、変わっていました。
現在の環境での状況を改めて報告したいと思います。
2021/07/25時点で以下のコードはエラーなく動いていることを確認しています。
追記2022/05/13:Python高速化! for文は遅いので、”これ”を使うと30倍早いですよ!【コピペで動く!】という記事を書きました。

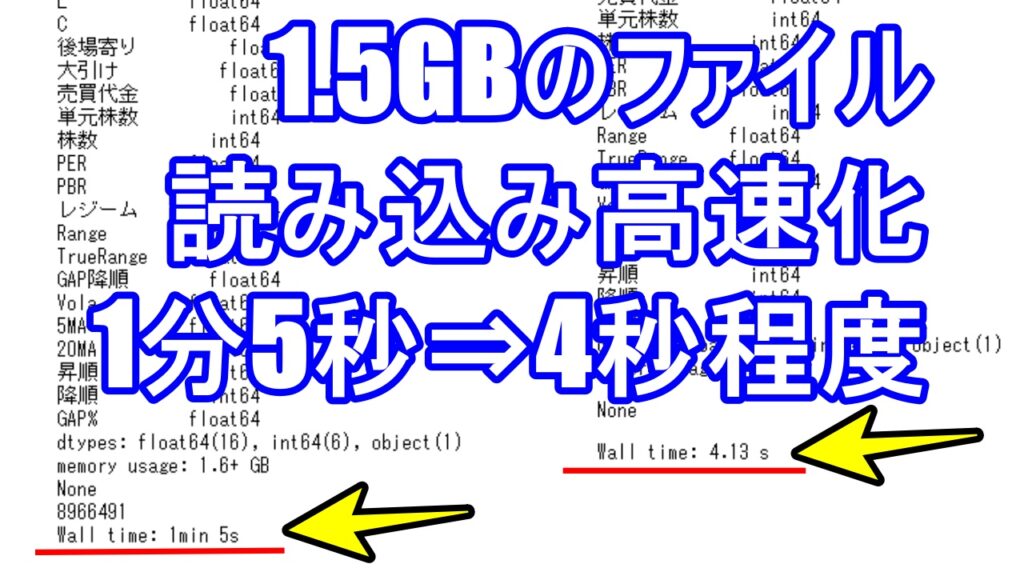
この記事を読むことで、csvファイル読み込みで1分5秒かかっていたものが4秒程度でデータを読み込めるようになります。大幅な速度・パフォーマンスの向上が期待できます。以下がその結果です。
読み込み時間 Wall time: 1 min 5 sec
読み込み時間 Wall time: 4 sec
今まで、Python 遅い と思っていたものが、こんなに早くなる と驚くことになるのではないでしょうか。使い方によってはすごく速くなります。
内容
Pythonでの作業の効率化の小技で、並列DataFrame処理で有名なDASKとオブジェクト保存のpickleを紹介します。以下の記事で、初心者、ビギナーの方が、Pythonを使ってcsvファイルの読み込みの速度・パフォーマンスを改善・向上することができます。
いわゆる時間のかかる前処理を”爆速化・高速化”し、分析の方により注力し、開発効率をあげるための小技の紹介になります。
今回の処理速度の計測には %%time というJupyter Notebook マジックコマンドを利用しています。
まず、DASKですが、基本的には並列処理・分散処理を行う分析ライブラリですが、私はcsvファイルの読み込みに使っています。調べるとメモリの使用量を抑えながら並列処理できるようなのですが、頻繁に使って、かつ時間がかかっているデータロードを高速化するために使っています。
解析には自分のPC(Windows10)の環境を利用しました。
では、実際の使用例を以下に示します。まずファイルの状況をまず、確認します。
import os
print(os.path.getsize('./out.csv'))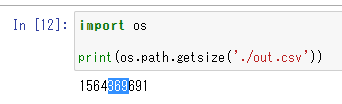
1564369691
約1.5GBのファイルを読み込んでみたいと思います。
%%time
import pandas as pd
input_file_csv = "./out.csv"
df_csv=pd.read_csv(input_file_csv, encoding='utf-8',index_col=0,parse_dates=True)
display(df_csv.tail())
print(df_csv.info())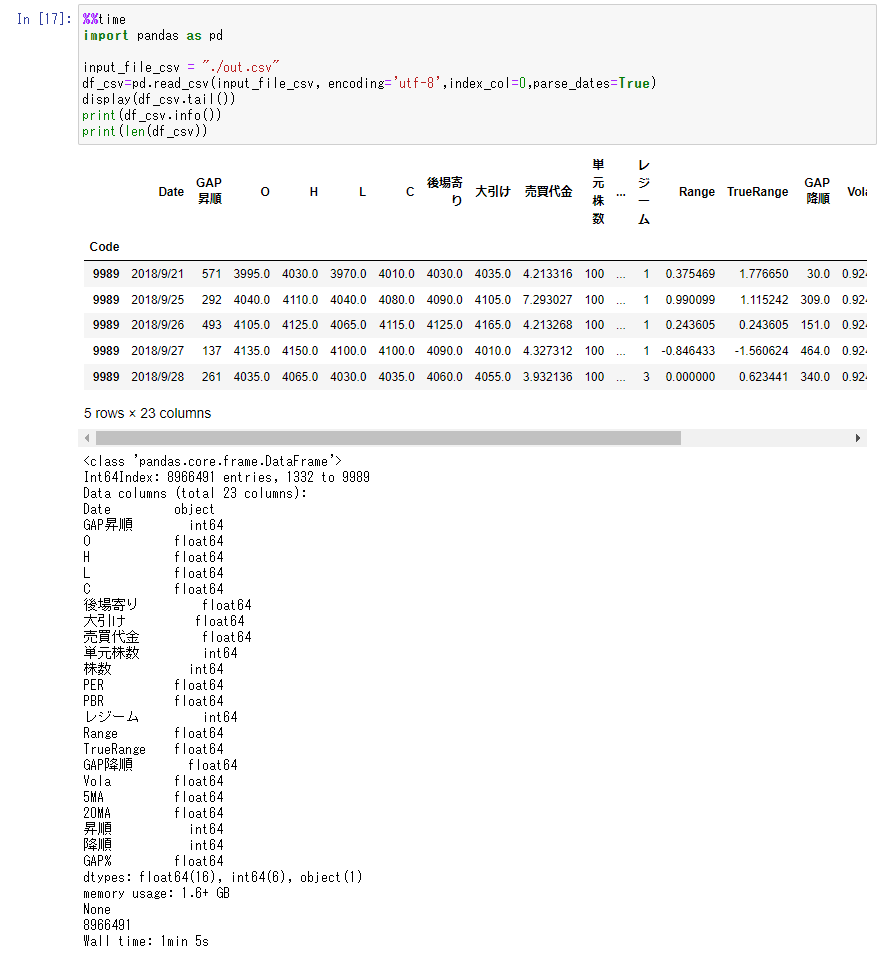
読み込み時間 Wall time: 1 min 5 sec
約900万行のデータで、読み込むのに1分5秒程度かかっています。
このようなファイルがたくさんあったり、毎回この作業をするのはちょっと、、というような場合があります。その時こそ、DASKです。
DASKのコードは以下の通りです。
%%time
import dask.dataframe as ddf
import dask.multiprocessing
df_dask = ddf.read_csv(input_file_csv,parse_dates=True,
dtype={'C': 'float64',
'H': 'float64',
'L': 'float64',
'O': 'float64',
'PBR': 'float64',
'PER': 'float64',
'後場寄り': 'float64',
'大引け': 'float64'})
df_dask = df_dask.compute()
display(df_dask.tail())
print(df_dask.info())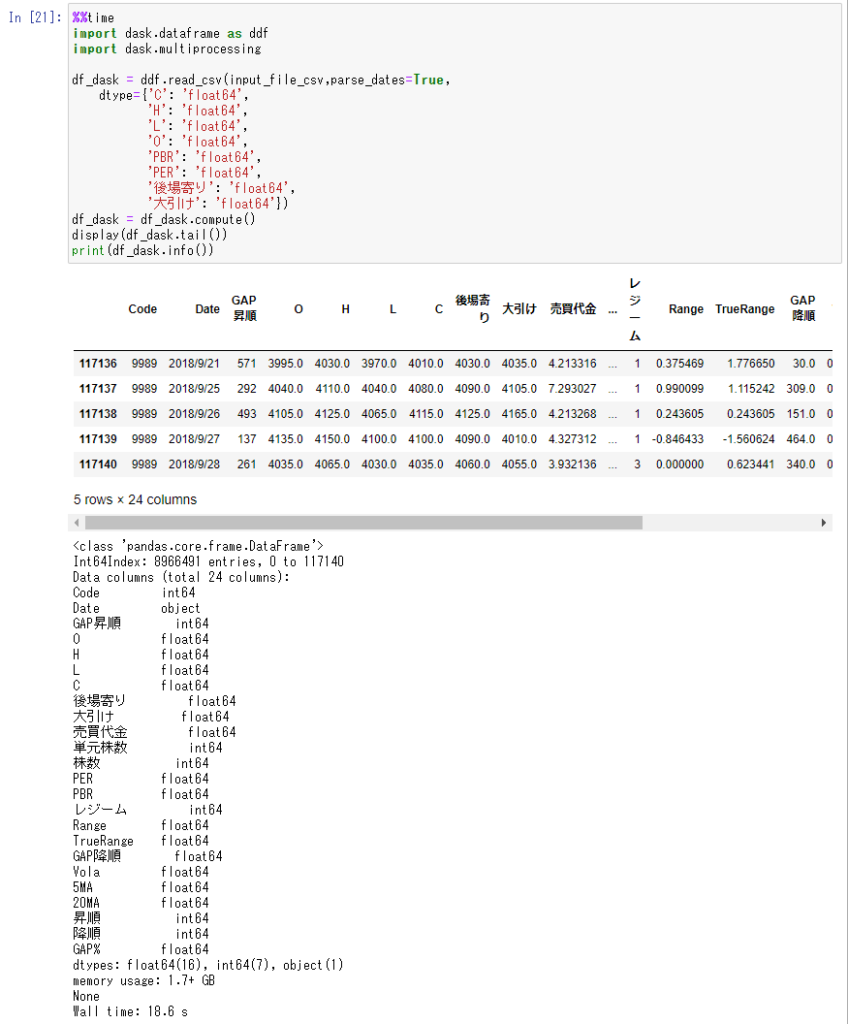
読み込み時間 Wall time: 18 sec
同じファイルの読み込みに19秒です。高速化成功です。
これならもう少し大きなファイルでデータをもらうようなことがあっても、データの下準備や前処理ではなく、データ解析のほうに自分の時間が使えそうです。
さらに大きなファイルやデータの場合はpickleを使うと便利です。
たとえば、大きなデータを解析していて、翌日に同じところから始めたいと思うようなことがあります。折角時間をかけてデータロードしたDataFrameも明日の朝に再度データロードからやり直しかと思うとちょっと気が重いですよね、、でも、pickleがあれば大丈夫です。
使い方は簡単で、DataFrameをpicleファイルに保存して、それを使いたいときに読み込めばいいのです。使い方は以下の通りです。
import pickle
df_csv.to_pickle('./dataout_out.pickle')
print(os.path.getsize('./dataout_out.pickle'))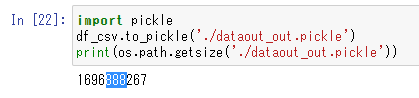
1696888267
約1.7GBのファイルにDataFrameの内容が書き出されます。明日の朝と思いながらそのファイルを読み込んでみましょう。
%%time
import pickle
with open('./dataout_out.pickle', mode='rb') as fp :
df_pickle = pickle.load(fp)
display(df_pickle.info())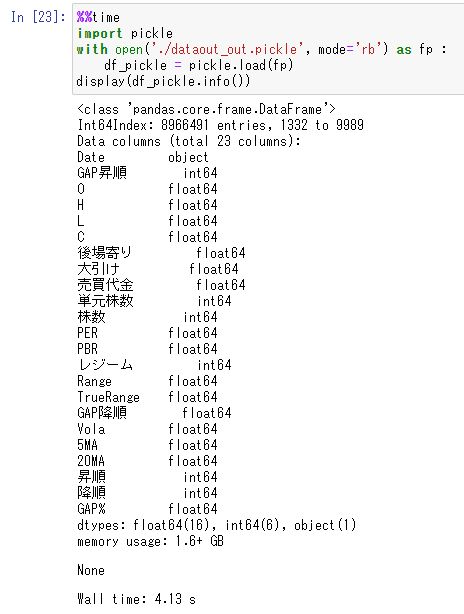
読み込み時間 Wall time:4 sec
なんと、4秒です。通常のcvsファイルの読み込みから比べるとあっという間ですね。データの種類や構造・サイズによって変わるとは思いますが、効率の明らかな改善が見込まれる場合など、これを使わない手はないです。
二つのモジュールとももっといろいろな機能があるようですが、とりあえず、簡単に作業効率を上げられる小技でした。
この記事が今後の投資活動において、お役に立つことを願っています。
この部分はどうなのか、ここを知りたいのだが、、というような希望があればご連絡いただければ幸いです。すべてにこたえられるかは分かりませんが、是非前向きに検討してみようと思います。
また、短い文でも構いませんので、感想などいただけるとモチベーションの向上、今後の改善への励みになりますので、是非ともよろしくお願いいたします。
最後まで読んでいただき、大変ありがとうございました。
関連記事:
Python高速化! for文は遅いので、”これ”を使うと30倍早いですよ!【コピペで動く!】
---
Python・投資関係







IB証券


コメント